


Java 异常类层次结构图概览
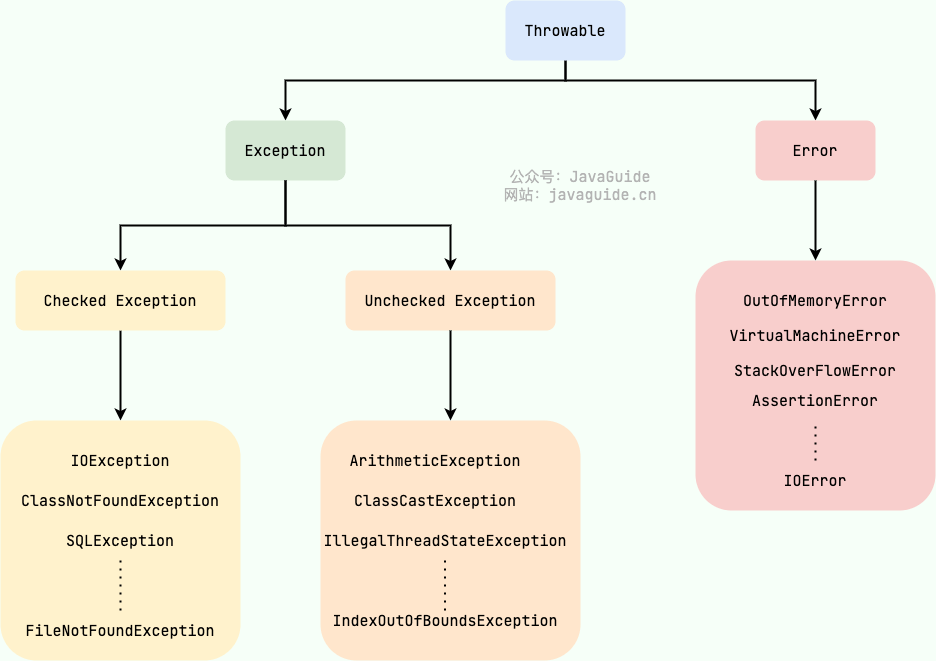
Exception 和 Error 有什么区别?
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
-
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。 -
Error:Error属于程序无法处理的错误 ,我们没办法通过不建议通过catch来进行捕获catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
Checked Exception 和 Unchecked Exception 有什么区别?
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
比如下面这段 IO 操作的代码:
![图片[2]| Java基础常见面试题总结(3)| 小妖客栈](https://picture.wangkay.tech//Strapi/202404272251510.png)
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException...。
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
RuntimeException 及其子类都统称为非受检查异常,常见的有(建议记下来,日常开发中会经常用到):
-
NullPointerException(空指针错误) -
IllegalArgumentException(参数错误比如方法入参类型错误) -
NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类) -
ArrayIndexOutOfBoundsException(数组越界错误) -
ClassCastException(类型转换错误) -
ArithmeticException(算术错误) -
SecurityException(安全错误比如权限不够) -
UnsupportedOperationException(不支持的操作错误比如重复创建同一用户) -
……
![图片[3]| Java基础常见面试题总结(3)| 小妖客栈](https://picture.wangkay.tech//Strapi/202404272251338.png)
Throwable 类常用方法有哪些?
-
String getMessage(): 返回异常发生时的简要描述 -
String toString(): 返回异常发生时的详细信息 -
String getLocalizedMessage(): 返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同 -
void printStackTrace(): 在控制台上打印Throwable对象封装的异常信息
try-catch-finally 如何使用?
-
try块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。 -
catch块:用于处理 try 捕获到的异常。 -
finally块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
代码示例:
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
} finally {
System.out.println("Finally");
}
输出:
Try to do something
Catch Exception -> RuntimeException
Finally
注意:不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
中有明确提到:
If the
tryclause executes a return, the compiled code does the following:
Saves the return value (if any) in a local variable.
Executes a jsr to the code for the
finallyclause.Upon return from the
finallyclause, returns the value saved in the local variable.
代码示例:
public static void main(String[] args) {
System.out.println(f(2));
}
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}
输出:
0
finally 中的代码一定会执行吗?
不一定的!在某些情况下,finally 中的代码不会被执行。
就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
// 终止当前正在运行的Java虚拟机
System.exit(1);
} finally {
System.out.println("Finally");
}
输出:
Try to do something
Catch Exception -> RuntimeException
另外,在以下 2 种特殊情况下,finally 块的代码也不会被执行:
-
程序所在的线程死亡。
-
关闭 CPU。
相关 issue:https://github.com/Snailclimb/JavaGuide/issues/190。
🧗🏻 进阶一下:从字节码角度分析try catch finally这个语法糖背后的实现原理。
如何使用 try-with-resources 代替try-catch-finally?
-
适用范围(资源的定义): 任何实现
java.lang.AutoCloseable或者java.io.Closeable的对象 -
关闭资源和 finally 块的执行顺序: 在
try-with-resources语句中,任何 catch 或 finally 块在声明的资源关闭后运行
《Effective Java》中明确指出:
面对必须要关闭的资源,我们总是应该优先使用
try-with-resources而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
Java 中类似于InputStream、OutputStream、Scanner、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下:
//读取文本文件的内容
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}
使用 Java 7 之后的 try-with-resources 语句改造上面的代码:
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}
当然多个资源需要关闭的时候,使用 try-with-resources 实现起来也非常简单,如果你还是用try-catch-finally可能会带来很多问题。
通过使用分号分隔,可以在try-with-resources块中声明多个资源。
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}
异常使用有哪些需要注意的地方?
-
不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
-
抛出的异常信息一定要有意义。
-
建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出
NumberFormatException而不是其父类IllegalArgumentException。 -
避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
-
……
泛型
什么是泛型?有什么作用?
Java 泛型(Generics) 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。
编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 ArrayList<Person> persons = new ArrayList<Person>() 这行代码就指明了该 ArrayList 对象只能传入 Person 对象,如果传入其他类型的对象就会报错。
ArrayList<E> extends AbstractList<E>
并且,原生 List 返回类型是 Object ,需要手动转换类型才能使用,使用泛型后编译器自动转换。
泛型的使用方式有哪几种?
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);
2.泛型接口:
public interface Generator<T> {
public T method();
}
实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}
实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}
3.泛型方法:
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
使用:
// 创建不同类型数组:Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );
注意:
public static < E > void printArray( E[] inputArray )一般被称为静态泛型方法;在 java 中泛型只是一个占位符,必须在传递类型后才能使用。类在实例化时才能真正的传递类型参数,由于静态方法的加载先于类的实例化,也就是说类中的泛型还没有传递真正的类型参数,静态的方法的加载就已经完成了,所以静态泛型方法是没有办法使用类上声明的泛型的。只能使用自己声明的<E>
项目中哪里用到了泛型?
-
自定义接口通用返回结果
CommonResult<T>通过参数T可根据具体的返回类型动态指定结果的数据类型 -
定义
Excel处理类ExcelUtil<T>用于动态指定Excel导出的数据类型 -
构建集合工具类(参考
Collections中的sort,binarySearch方法)。 -
……
反射
关于反射的详细解读,请看这篇文章 。
何谓反射?
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射的优缺点?
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利。
不过,反射让我们在运行时有了分析操作类的能力的同时,也增加了安全问题,比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
相关阅读: 。
反射的应用场景?
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。但是!这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。
比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 Method 来调用指定的方法。
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
System.out.println("after method " + method.getName());
return result;
}
}
另外,像 Java 中的一大利器 注解 的实现也用到了反射。
为什么你使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
注解
何谓注解?
Annotation (注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。
注解本质是一个继承了Annotation 的特殊接口:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
public interface Override extends Annotation{
}
JDK 提供了很多内置的注解(比如 @Override、@Deprecated),同时,我们还可以自定义注解。
注解的解析方法有哪几种?
注解只有被解析之后才会生效,常见的解析方法有两种:
-
编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 -
运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
SPI
关于 SPI 的详细解读,请看这篇文章 。
何谓 SPI?
SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
![图片[4]| Java基础常见面试题总结(3)| 小妖客栈](https://picture.wangkay.tech//Strapi/202404272251337.jpeg)
SPI 和 API 有什么区别?
那 SPI 和 API 有啥区别?
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
![图片[5]| Java基础常见面试题总结(3)| 小妖客栈](https://picture.wangkay.tech//Strapi/202404272253621.png)
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
SPI 的优缺点?
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
-
需要遍历加载所有的实现类,不能做到按需加载,这样效率还是相对较低的。
-
当多个
ServiceLoader同时load时,会有并发问题。
序列化和反序列化
关于序列化和反序列化的详细解读,请看这篇文章 ,里面涉及到的知识点和面试题更全面。
什么是序列化?什么是反序列化?
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
简单来说:
-
序列化:将数据结构或对象转换成二进制字节流的过程
-
反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
下面是序列化和反序列化常见应用场景:
-
对象在进行网络传输(比如远程方法调用 RPC 的时候)之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化;
-
将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化;
-
将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序列化;
-
将对象存储到内存之前需要进行序列化,从内存中读取出来之后需要进行反序列化。
维基百科是如是介绍序列化的:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
![图片[6]| Java基础常见面试题总结(3)| 小妖客栈](https://picture.wangkay.tech//Strapi/202404272253923.png)
序列化协议对应于 TCP/IP 4 层模型的哪一层?
我们知道网络通信的双方必须要采用和遵守相同的协议。TCP/IP 四层模型是下面这样的,序列化协议属于哪一层呢?
-
应用层
-
传输层
-
网络层
-
网络接口层
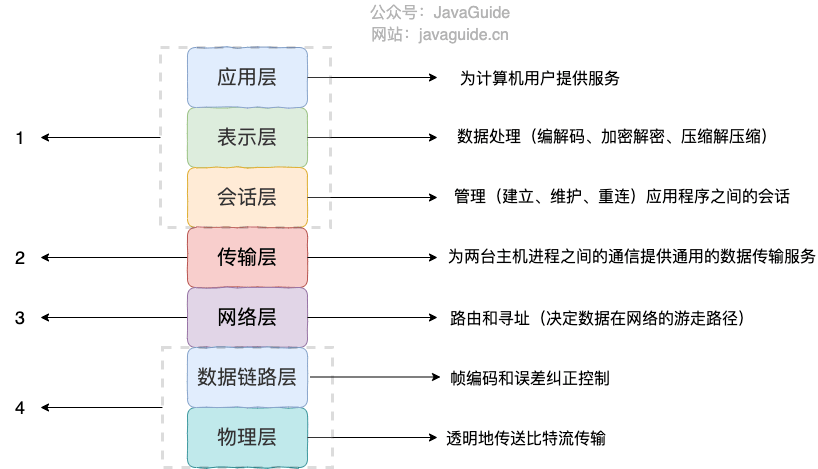
如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
因为,OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序列化协议属于 TCP/IP 协议应用层的一部分。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
-
transient只能修饰变量,不能修饰类和方法。 -
transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。 -
static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
常见序列化协议有哪些?
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存在安全问题。比较常用的序列化协议有 Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。
像 JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差,一般不会选择。
为什么不推荐使用 JDK 自带的序列化?
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
-
不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
-
性能差:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
-
存在安全问题:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读: 。
I/O
关于 I/O 的详细解读,请看下面这几篇文章,里面涉及到的知识点和面试题更全面。
Java IO 流了解吗?
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
-
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。 -
OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
I/O 流为什么要分为字节流和字符流呢?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
个人认为主要有两点原因:
-
字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时;
-
如果我们不知道编码类型的话,使用字节流的过程中很容易出现乱码问题。
Java IO 中的设计模式有哪些?
参考答案:
BIO、NIO 和 AIO 的区别?
参考答案:
语法糖
什么是语法糖?
语法糖(Syntactic sugar) 代指的是编程语言为了方便程序员开发程序而设计的一种特殊语法,这种语法对编程语言的功能并没有影响。实现相同的功能,基于语法糖写出来的代码往往更简单简洁且更易阅读。
举个例子,Java 中的 for-each 就是一个常用的语法糖,其原理其实就是基于普通的 for 循环和迭代器。
String[] strs = {"JavaGuide", "公众号:JavaGuide", "博客:https://javaguide.cn/"};
for (String s : strs) {
System.out.println(s);
}
不过,JVM 其实并不能识别语法糖,Java 语法糖要想被正确执行,需要先通过编译器进行解糖,也就是在程序编译阶段将其转换成 JVM 认识的基本语法。这也侧面说明,Java 中真正支持语法糖的是 Java 编译器而不是 JVM。如果你去看com.sun.tools.javac.main.JavaCompiler的源码,你会发现在compile()中有一个步骤就是调用desugar(),这个方法就是负责解语法糖的实现的。
Java 中有哪些常见的语法糖?
Java 中最常用的语法糖主要有泛型、自动拆装箱、变长参数、枚举、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等。
关于这些语法糖的详细解读,请看这篇文章














暂无评论内容