


这篇文章我们先介绍一下分布式锁的基本概念。
为什么需要分布式锁?
在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
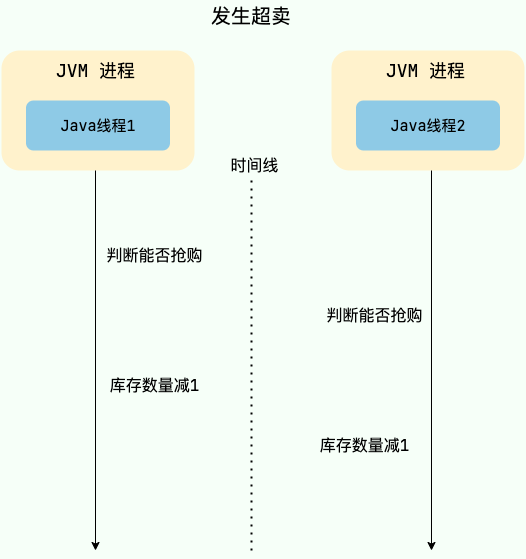
举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
-
线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
-
线程 1 查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
-
线程 2 也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
-
线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
-
线程 2 继续执行,将库存数量减少 1 个,然后返回成功。
-
此时就发生了超卖问题,导致商品被多卖了一份。
为了保证共享资源被安全地访问,我们需要使用互斥操作对共享资源进行保护,即同一时刻只允许一个线程访问共享资源,其他线程需要等待当前线程释放后才能访问。这样可以避免数据竞争和脏数据问题,保证程序的正确性和稳定性。
如何才能实现共享资源的互斥访问呢? 锁是一个比较通用的解决方案,更准确点来说是悲观锁。
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
对于单机多线程来说,在 Java 中,我们通常使用 ReentrantLock 类、synchronized 关键字这类 JDK 自带的 本地锁 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
下面是我对本地锁画的一张示意图。
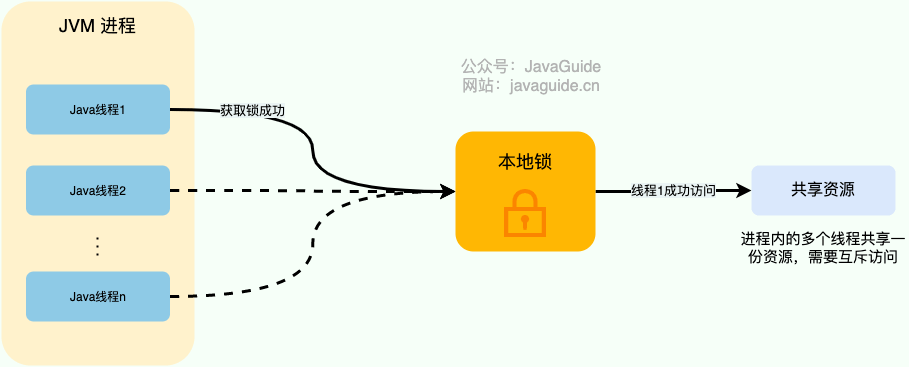
从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,分布式锁 就诞生了。
举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。用户下订单之前需要检查库存,为了防止超卖,这里需要加锁以实现对检查库存操作的同步访问。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作了。我们需要用到分布式锁,这样的话,即使多个线程不在同一个 JVM 进程中也能获取到同一把锁,进而实现共享资源的互斥访问。
下面是我对分布式锁画的一张示意图。
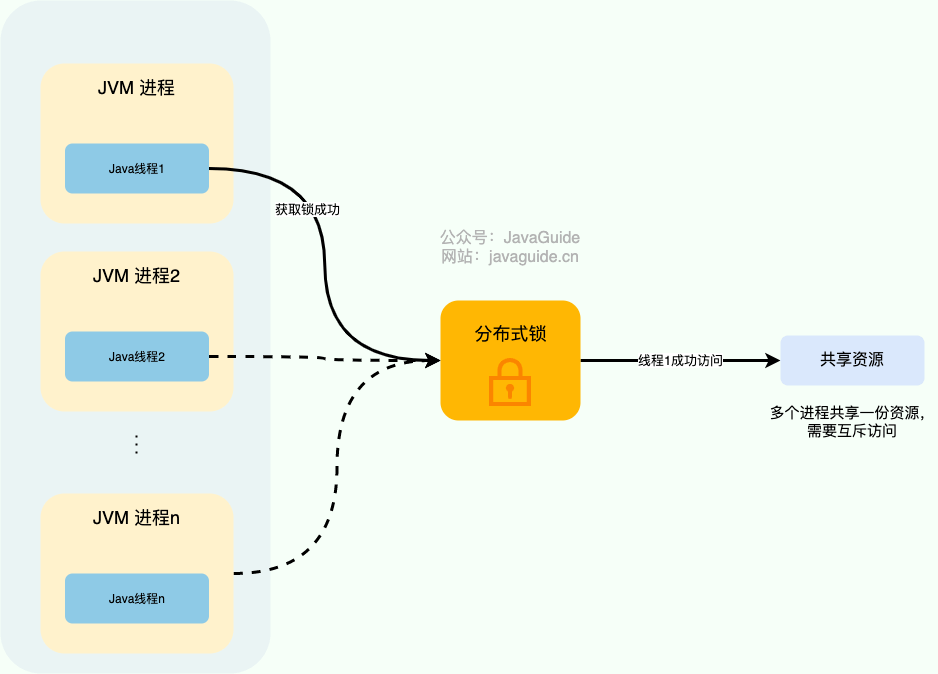
从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
分布式锁应该具备哪些条件?
一个最基本的分布式锁需要满足:
-
互斥:任意一个时刻,锁只能被一个线程持有。
-
高可用:锁服务是高可用的,当一个锁服务出现问题,能够自动切换到另外一个锁服务。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。这一般是通过超时机制实现的。
-
可重入:一个节点获取了锁之后,还可以再次获取锁。
除了上面这三个基本条件之外,一个好的分布式锁还需要满足下面这些条件:
-
高性能:获取和释放锁的操作应该快速完成,并且不应该对整个系统的性能造成过大影响。
-
非阻塞:如果获取不到锁,不能无限期等待,避免对系统正常运行造成影响。
分布式锁的常见实现方式有哪些?
常见分布式锁实现方案如下:
-
基于关系型数据库比如 MySQL 实现分布式锁。
-
基于分布式协调服务 ZooKeeper 实现分布式锁。
-
基于分布式键值存储系统比如 Redis 、Etcd 实现分布式锁。
关系型数据库的方式一般是通过唯一索引或者排他锁实现。不过,一般不会使用这种方式,问题太多比如性能太差、不具备锁失效机制。
基于 ZooKeeper 或者 Redis 实现分布式锁这两种实现方式要用的更多一些,我专门写了一篇文章来详细介绍这两种方案:。
总结
这篇文章我们主要介绍了:
-
分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
-
分布式锁的应该具备的条件:互斥、高可用、可重入、高性能、非阻塞。
-












暂无评论内容